#python randint function
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has a 66 index score for customer satisfaction in the US.
Text
Hyperparameter Tuning in Machine Learning: Techniques and Tools

What is Hyperparameter Tuning?
Hyperparameter tuning is the process of selecting the best combination of hyperparameters for a machine learning model to improve its performance.
Unlike parameters, which are learned from the data during training (e.g., weights in neural networks), hyperparameters are set before training and control aspects of the learning process, such as the complexity of the model, the learning rate, and the number of iterations.
Effective hyperparameter tuning can make a significant difference in a model’s performance. The process involves experimenting with different hyperparameter values, training the model, and evaluating its performance to find the optimal set.
2. Common Hyperparameters in Machine Learning Different types of machine learning algorithms have different hyperparameters.
Below are examples of common hyperparameters for some popular algorithms: Linear Models (e.g., Linear Regression, Logistic Regression): Regularization strength (e.g., L1 or L2 penalties) Learning rate (for gradient descent)
Decision Trees:
Maximum depth of the tree Minimum samples required to split a node Minimum samples required at a leaf node Support Vector Machines (SVM): Kernel type (linear, polynomial, RBF) Regularization parameter © Gamma value for RBF kernel Neural Networks:
Number of layers and neurons per layer Learning rate Dropout rate (for regularization) Batch size Random Forests:
Number of trees in the forest Maximum depth of each tree Minimum samples required to split nodes Each of these hyperparameters affects how the model learns, generalizes, and fits the data.
3. Techniques for Hyperparameter Tuning
There are several techniques for hyperparameter tuning, each with its strengths and limitations:
a) Grid Search Grid search is a brute-force method for hyperparameter tuning. In grid search, you define a grid of possible hyperparameter values and systematically evaluate all combinations to find the best one.
For example, you might test various learning rates and regularization values for a logistic regression model.
Advantages:
Simple and exhaustive; covers all combinations in the search space.
Easy to implement using libraries like scikit-learn.
Disadvantages:
Computationally expensive, especially when the hyperparameter space is large. Can be time-consuming, as all combinations are evaluated regardless of their effectiveness.
Example:
python
from sklearn.model_selection import GridSearchCV from sklearn.svm import SVC param_grid = {‘C’: [0.1, 1, 10], ‘kernel’: [‘linear’, ‘rbf’]} grid_search = GridSearchCV(SVC(), param_grid, cv=5) grid_search.fit(X_train, y_train) print(“Best parameters:”, grid_search.best_params_)
b) Random Search Random search randomly selects hyperparameter combinations from a defined search space. Unlike grid search, it doesn’t evaluate all combinations but selects a subset, which can lead to quicker results, especially for large search spaces.
Advantages:
More efficient than grid search, especially when the hyperparameter space is large. Less computationally expensive and faster than grid search.
Disadvantages:
No guarantee of finding the optimal set of hyperparameters, as it only evaluates a random subset.
Example:
python
from sklearn.model_selection import RandomizedSearchCV from sklearn.ensemble import RandomForestClassifier from scipy.stats import randint param_dist = {‘n_estimators’: randint(10, 200), ‘max_depth’: randint(1, 20)} random_search = RandomizedSearchCV(RandomForestClassifier(), param_dist, n_iter=100, cv=5) random_search.fit(X_train, y_train) print(“Best parameters:”, random_search.best_params_)
c) Bayesian Optimization Bayesian optimization is a probabilistic model-based method that uses past evaluation results to guide the search for the best hyperparameters.
It builds a probabilistic model of the objective function (usually the validation score) and uses it to choose the next set of hyperparameters to evaluate.
Advantages:
More efficient than grid search and random search, especially for expensive-to-evaluate functions.
Can converge to an optimal solution faster with fewer evaluations.
Disadvantages: Requires specialized libraries (e.g., GaussianProcessRegressor from scikit-learn).
Computational overhead to build the probabilistic model. d) Genetic Algorithms Genetic algorithms use principles of natural selection (like mutation, crossover, and selection) to explore the hyperparameter search space.
These algorithms work by generating a population of candidate solutions (hyperparameter combinations) and evolving them over several generations to find the optimal solution.
Advantages: Can handle complex search spaces.
Effective in exploring both continuous and discrete hyperparameter spaces.
Disadvantages: Computationally intensive. Requires careful tuning of genetic algorithm parameters.
4. Tools for Hyperparameter Tuning
There are several tools and libraries that simplify the hyperparameter tuning process:
a) Scikit-learn Scikit-learn provides easy-to-use implementations for grid search (GridSearchCV) and random search (RandomizedSearchCV).
It also offers tools for cross-validation to ensure that hyperparameter tuning results are reliable.
b) Optuna Optuna is an open-source hyperparameter optimization framework that offers features like automatic pruning of unpromising trials and parallelization.
It supports various optimization algorithms, including Bayesian optimization.
c) Hyperopt Hyperopt is another Python library for optimizing hyperparameters using Bayesian optimization and random search. It supports parallelization and can be used with a variety of machine learning frameworks.
d) Ray Tune Ray Tune is a scalable hyperparameter tuning framework built on Ray, which provides efficient support for distributed hyperparameter optimization, including advanced search algorithms like Hyperband.
e) Keras Tuner For deep learning models, Keras Tuner is a library specifically designed for tuning hyperparameters of Keras models.
It integrates seamlessly with TensorFlow and supports methods like random search, Hyperband, and Bayesian optimization.
5. Best Practices for Hyperparameter Tuning To make the process more efficient and effective, here are some best practices:
Use cross-validation:
This ensures that your hyperparameter tuning results are reliable and not overfitted to a single train-test split.
Start simple:
Begin with a smaller, manageable search space and progressively increase complexity if necessary.
Parallelization:
Tools like Ray Tune and Optuna allow you to run multiple hyperparameter tuning jobs in parallel, speeding up the process.
Monitor performance:
Keep track of how different hyperparameter sets affect model performance, and use visualization tools to analyze the results.
6. Conclusion Hyperparameter tuning is a crucial part of machine learning model optimization.
Whether you’re working with a simple linear model or a complex deep learning architecture, finding the right hyperparameters can significantly improve model performance.
By leveraging techniques like grid search, random search, and Bayesian optimization, along with powerful tools like scikit-learn, Optuna, and Keras Tuner, you can efficiently find the best set of hyperparameters for your model.
WEBSITE: https://www.ficusoft.in/data-science-course-in-chennai/
0 notes
Text
youtube
!! Numpy Random Module !!
#Shiva#python tutorials#data analytics tutorials#numpy tutorials#numpy random#random module in numpy python#random function numpy#python randint function#python randn function#python numpy random choice function#python numpy random uniform function#how to create random array in numpy python#random number generator#python array numpy#generate a random number#rand number#random function#randint python#numpy for machine learning#numpy data science#python numpy#Youtube
0 notes
Note
Hey!! Thanks for your time. So I was wondering how I would write the code for something where I want the chances of success to be based on a percentage. I'm trying to implement lottery tickets, and I need it to have a 0.09% chance of success. And also, how would I make it so you get a different response for each outcome? Like if you failed to get one, I want your buddy to say "aw that's too bad, maybe next time!" And if not I want everyone to freak out, plus the earnings to be added. Thank you!!
I return from the void now that everyone is migrating back from the land of the South African Muskrat! Yours is a rather involved answer to see all of it below the cut
The answer to your question, at least the percentage part, is a matter of the randint() function in the Python library. In this case, you want something to happen only 1 in so many times. For example, 1 in 10 is a 10% chance. To simulate this in code, you can have the interpreter pick a random(note this isn’t true randomness, but it’s good enough for a video game we aren’t making a cyber security system!) number between 1 and 10. If it comes out to one number and one number only, then you pass the check. This makes it a 10% chance, just like if you rolled a 10 sided die.
For your .09% chance(very rare!), it would be 1 in ~1,100 chance.(.090909...%). So if you have Python pick a number between 1 and 1,100 and check to see if it’s one specific number, then you’ll have your lottery win.
The easiest way to implement this in game is to record the results of the 1 in 1,100 chance inside a function wrapper so that you can call it multiple times and they can check lots of tickets.
init python: def Lottery_Ticket(): ticket_num = renpy.random.randint(1, 1100) return ticket_num
In order to use the randint() function from the random library, you just need to invoke it! It’s a part of Renpy’s library. So you’d type renpy.random.randint(1,1100) like above. :)
Once that is done in your game code itself you’ll put the logic for the winning number. Let’s say it’s 42, for meme reasons.
You could write in your game file:
label check_ticket: $ ticket = Lottery_Ticket() if ticket == 42: jump you_win else: jump you_lose
This simple logic sets the ticket equal to the result of the Lottery_Ticket function. It then checks if the number is exactly the winning number you chose. If so, it takes you to the winning section of your game code, if not, it falls through and says you lose.
Every time they buy a ticket, you can send them to this label, it will re-run the Lottery_Ticket function anew, picking a new random number, and see if they won.
Under your winning code, since you asked, this is where you’d put your characters reacting positively! Note the thing in brackets is the player character’s name as a variable being interpolated by the engine. If you let the player pick their own name, that’s how you’d get it into the script. If they have a set name, just type that instead.
label you_win: e “Oh my God! [PC_Name] you did it! e “It’s like a dream come true!” $ Inv.add(lottery_winnings) $ renpy.notify(”You added“ + str(lottery_winnings) + “ to your wallet!”)
As you see, I’m using to functions. One that comes with Ren’Py calls in the notify screen context through the function. It needs to be a string inside which is why I’ve turned the int representing the lottery winnings into a string here.(This assumes you have a variable called “lottery_winnings” that has a specific integer value! Please initialize one before the start of your game!) (example: $ lottery_winnings = 10000)
The second is me assuming that you have an Inventory class instance with a method called “add” that can add money into a wallet variable. To make something like that:
init python: class Inventory(python_object): def__init__(self, wallet = 0): self.wallet = wallet self.pocket = [] def add(num): self.wallet += num return self.wallet
Then you just need an instance of it:$ Inv = Inventory() (I wrote it with defaults, so you don’t need to pass any arguments to the instance when you make it, though you are welcome to pass an INTEGER to it when you instantiate it so that your character starts with a certain amount of money. :D )
Then you can call the method on the variable to add the earnings to their wallet. :)
There’s also an empty pockets list inside of the inventory you can use to store the string names of objects they also own. For something like that:
$ Inv.pocket.append(”apple”)
This will add a string called “apple” to the pocket list inside the inventory. Which you can use to check if they “own” an object by checking if it is in the list.
if ‘apple’ in Inv.pocket: .......
But that’s more detail for another time.
You need to put the class in an init python block before the game starts so that you can make an instance of it to manipulate later.
For not winning, just have the ‘you_lose’ label have the dialogue you wanted.
label you_lose: e “Aw, that’s too bad. Maybe next time!”
And then continue on with the rest of the game.
I hope everything here is clear and this helps. I know this ask came in ages ago, but I still think answering it will help Ren’Py users in the now. Remember: If your code won’t compile, and you don’t what to do; who you gonna call? The Ren’Py Help Desk!
#RenPy#Ren'Py#thehelpdesk#Renpyhelpdesk#keyword: python#keyword: init python#Python#Python Classes#Inventory Code#function: renpy.notify()#function: renpy.random.randint()#keyword: jump#keyword: label
14 notes
·
View notes
Text
Modules in Python
People have built tools in Python that are not included automatically when you install it. Python allows us to package code into files (or sets of files) called modules.
A module is a collection of Python declarations intended broadly to be used as a tool. Modules are also called libraries or packages. A package is really a directory that holds a collection of modules.
To use a module in a file:

Often a library will include a lot of code that you don’t need that may slow down the program or conflict with existing code. Therefore, only import what you need.
One common library that comes as part of the Python Standard Library is datetime. In this case, datetime is the name of the libary and the object you import.

There are hundres of modules that you can use. Another one of the most commonly used modules is random which allows you to generate numbers or select items at random.
If using more than one piece of the module’s functionality, use:

Two common random functions are:
random.choice() takes a list as an argument and returns a number from the list
random.randint() takes two numbers as arguments and generates a random number between the two numbers you passed in

NOTE when we want to invoke the .randint() function, we call random.randint()
This is a default behaviour where Python offers a namespace for the module. A namespace isolates the functions, classes and variables defined in the module from the code in the file doing the importing. Your local namespace is where your code is run.
Python defaults to naming the namespace after the module being imported, but sometimes this name may be ambiguous of long. It could also conflict with an object you have defined in your local namespace.
This name can be altered by aliasing using as as a keyword.

Aliasing is most often done if the name of the library is long and typing it is laborious.
You might also occasionally encounter import *. * is known as a wildcard and matches everything and anything. This is dangerous because it could pollute our local namespace. Pollution occurs when the same name could apply to two possible things.
Another library is matplotlib which allows you to plot your Python code in 2D.
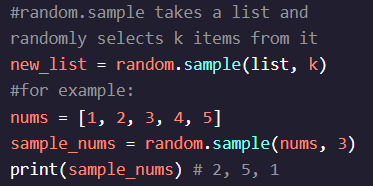
random.sample() is a random function that takes a range and a number as arguments and returns the specified number of random numbers from that range.


If you use Python’s built-in floating-point arithmetic to calculate a sum, it produces a weirdly formatted number.
Knowing that rounding errors occur in floating-point arithmetic, you want to use a data type that performs decimal arithmetic more accurately.

We use the decimal module’s Decimal data type to add. Because we used the Decimal type the math acts more as expected.
Usually, modules provide functions or data types that we can then use to solve a general problem, allowing us more time to focus on the software we are building to solve a more specific problem.
NOTE: Make sure to use quotes around the floats. Each number will need to be converted with Decimal BEFORE performing the operations.
If a variable is defined inside a function, it will not be accessible outside a function. Scope also applies to classes and to the files you are working within.
Even files inside the same directory do not have access to each other’s variables, functions, classes or any other code.
Files are actually modules, so you can give a file access to another file’s content using import.

0 notes
Text
EECS 1015: LAB #9 – Revisiting the MinMaxList (Importing classes and improving efficiency) Assigned: Solved
EECS 1015: LAB #9 – Revisiting the MinMaxList (Importing classes and improving efficiency) Assigned: Solved
LAB 9 – TASK/ Lab 9 – Improving MinMaxList efficiency STARTING CODE – main.py [https://trinket.io/python/44a3131856] from MinMaxList import MinMaxList # Import MinMaxList from separate file from random import randint # Main function is given. def main(): aList = MinMaxList([10, 11, 99, 1, 34, 88]) print(“–Insert Item–“) for i in range(30): x = randint(1,…

View On WordPress
0 notes
Text
Create a list of five random numbers. Use randint, don't hardcode. Demonstrate your algorithm finding each of the numbers
Create a list of five random numbers. Use randint, don’t hardcode. Demonstrate your algorithm finding each of the numbers
Sequential Search Algorithm Python Programming Objectives ---------- * sequential search - design, analyze, implement, test, time * continue practicing previously learned skills: algorithm analysis, graphing with theoretical prediction curves Implementation -------------- Write a function named sequential_search. It must have two parameters, a list to search and a value to search for. It must…
View On WordPress
0 notes
Text
MySQL: Deleting data
Completing the data lifecycle is often harder than originally expected: Deleting data can cost sometimes way more than inserting it in the first place. MySQL Partitions can offer a way out. We have an earlier post on the subject. A sample table, and a problem statement Let’s define a kind of log table, to which data is added with an auto_increment id value and some data. #! /usr/bin/env python3 from time import sleep from random import randint from multiprocessing import Process import click import MySQLdb import MySQLdb.cursors db_config = dict( host="localhost", user="kris", passwd="geheim", db="kris", cursorclass=MySQLdb.cursors.DictCursor, ) @click.group(help="Load and delete data using partitions") def sql(): pass @sql.command() def setup_tables(): sql_setup = [ "drop table if exists data", """ create table data ( id integer not null primary key auto_increment, d varchar(64) not null, e varchar(64) not null )""", "alter table data partition by range (id) ( partition p1 values less than (10000))", "insert into data (id, d, e) values ( 1, 'keks', 'keks' )", "commit", ] db = MySQLdb.connect(**db_config) for cmd in sql_setup: try: c = db.cursor() c.execute(cmd) except MySQLdb.OperationalError as e: click.echo(f"setup_tables: failed {e} with {cmd}.") sql()This is our basic Python framework for experimentation, using the click framework, and a command setup-tables. This command will run a number of SQL statements to initialize our log table named data. The log table has three columns: id, an auto_increment counter, and two columns d and e, each containing 64 characters of data. To get things started, we add an initial partition, containing all id-values below 10.000 and an initial row. If we were to add data to this table in a loop, we would increment our id-counter, and with InnoDB being what it is, all new rows will be added at the end of the table: We remember from ALTER TABLE for UUID that the physical order of any InnoDB table is by primary key - our id-counter. Now, if we were to expire old data, we would start to delete rows with the lowest id-values, so we would delete rows from the beginning of the table, or the left hand side of the B+-Tree. To keep the tree balanced, MySQL would have to execute balancing operations, which will be expensive, because rows are being shuffeled around in the tree. New data is added to the right hand side of the B+-Tree, while old data is being deleted at the left hand side. To keep the tree balanced, data is reshuffled, which is an expensive operation. Instead, we are defining partitions. In our case, we are using the simplest definition possible: A PARTITION BY RANGE on the primary key column. We are making bins of 10.000 rows each, because that is convenient for our demonstration here. Three processes We will be using the Python multiprocessing module to have three processes, an inserter(), a partitioner() and a dropper(). All of them are endless loops. The inserter will insert random new data rows into the table as fast as possible. The partitioner will make sure that we always have a sufficient number of empty new partitions for the inserter to continue. The dropper will limit the number of partitions with data by throwing the oldest partition away. We will have small piece of code that starts our processes: @sql.command() def start_processing(): proc_partition = Process(target=partitioner) proc_partition.start() proc_drop = Process(target=dropper) proc_drop.start() proc_insert = Process(target=inserter) proc_insert.start()The Inserter The Inserter is an endless loop that generates two random 64 character strings and inserts a new row into the database. Every 10 rows, we commit, every 1000 rows we print a message. def inserter(): counter = 0 step = 10 cmd = "insert into data (id, d, e) values( NULL, %(d)s, %(e)s )" db = MySQLdb.connect(**db_config) c = db.cursor() while True: data = { "d": "".join([chr(randint(97, 97 + 26)) for x in range(64)]), "e": "".join([chr(randint(97, 97 + 26)) for x in range(64)]), } c.execute(cmd, data) counter += 1 if counter % step == 0: db.commit() if counter % 1000 == 0: print(f"counter = {counter}")Without the other two threads, the inserter will generate 10.000 rows and then stop, because there is no MAXVALUE clause. The Partitioner The Partitioner is an endless loop that runs an ANALYZE TABLE data command to refresh the statistics, and then queries INFORMATION_SCHEMA.PARTITIONS for the five partitions with the highest PARTITION_ORDINAL_POSITION. If there are fewer than 5 partitions in total, we generate new partitions no matter what. If there are not at least 5 partitions with no rows int them, we create new partitions. If we did nothing, we wait for 1/10th of a second and then check again. The new partition gets a range expression with a limit 10.000 values higher than the highest one found, and the partition name is derived from the limit by dividing by 10.000. In code: def create_partition(db, next_name, next_limit): cmd = f"alter table data add partition ( partition {next_name} values less than ( {next_limit}))" print(f"cmd = {cmd}") c = db.cursor() c.execute(cmd)This will simply format and run an ALTER TABLE statement to add a new partition to the existing table. And the checking loop: def partitioner(): db = MySQLdb.connect(**db_config) c = db.cursor() while True: # force stats refresh c.execute("analyze table kris.data") # find the five highest partitions cmd = """select partition_name, partition_ordinal_position, partition_description, table_rows from information_schema.partitions where table_schema = "kris" and table_name = "data" order by partition_ordinal_position desc limit 5 """ c.execute(cmd) rows = c.fetchall() next_limit = int(rows[0]["PARTITION_DESCRIPTION"]) + 10000 next_name = "p" + str(int(next_limit / 10000)) if len(rows) < 5: print(f"create {next_name} reason: not enough partitions") create_partition(db, next_name, next_limit) continue sum = 0 for row in rows: sum += int(row["TABLE_ROWS"]) if sum > 0: print(f"create {next_name} reason: not enough empty partitions") create_partition(db, next_name, next_limit) continue sleep(0.1)This code is mostly a long SELECT on the INFORMATION_SCHEMA.PARTITIONS table, and then two quick checks to see if we need to make more partitions. The Dropper The Dropper structurally mirrors the Partitioner: We have a tiny function to create the actual ALTER TABLE data DROP PARTITION statement: def drop_partition(db, partition_name): cmd = f"alter table data drop partition {partition_name}" c = db.cursor() print(f"cmd = {cmd}") c.execute(cmd)And we have an endless loop that basically runs a SELECT on INFORMATION_SCHEMA.PARTITIONS and checks the number of partitions that have a non-zero number of TABLE_ROWS. If it is too many, we drop the one with the lowest number (“the first one found”, using an appropriate sort order in our SQL). def dropper(): db = MySQLdb.connect(**db_config) c = db.cursor() while True: # force stats refresh c.execute("analyze table kris.data") # cmd = """ select partition_name, partition_ordinal_position, partition_description, table_rows from information_schema.partitions where table_schema = "kris" and table_name = "data" and table_rows > 0 order by partition_ordinal_position asc """ c.execute(cmd) rows = c.fetchall() if len(rows) >= 10: partition_name = rows[0]["PARTITION_NAME"] print(f"drop {partition_name} reason: too many partitions with data") drop_partition(db, partition_name) continue sleep(0.1)A test run In our test run, we see immediately after startup how the five spare partitions are being created. $ ./partitions.py setup-tables $ ./partitions.py start-processing create p2 reason: not enough partitions cmd = alter table data add partition ( partition p2 values less than ( 20000)) create p3 reason: not enough partitions cmd = alter table data add partition ( partition p3 values less than ( 30000)) create p4 reason: not enough partitions cmd = alter table data add partition ( partition p4 values less than ( 40000)) create p5 reason: not enough partitions cmd = alter table data add partition ( partition p5 values less than ( 50000)) create p6 reason: not enough empty partitions cmd = alter table data add partition ( partition p6 values less than ( 60000)) counter = 1000 counter = 2000 counter = 3000 ...Once we cross the threshold of p1, the number of empty partitions is no longer low enough and another one is being created: ... counter = 9000 counter = 10000 create p7 reason: not enough empty partitions cmd = alter table data add partition ( partition p7 values less than ( 70000)) counter = 11000 ...This continues for a while, until we have a sufficient number of data partitions so that we begin dropping, too: ... counter = 90000 create p15 reason: not enough empty partitions cmd = alter table data add partition ( partition p15 values less than ( 150000)) drop p1 reason: too many partitions with data cmd = alter table data drop partition p1 counter = 91000 counter = 92000 ...Now the system reaches a stable state and will add and drop partitions in sync with the Inserter. From inside SQL we can see the number of rows in the table rise, and then suddenly drop by 10.000 as we drop a partition. kris@localhost [kris]> select count(*) from data; +----------+ | count(*) | +----------+ | 89872 | +----------+ 1 row in set (0.00 sec) kris@localhost [kris]> select count(*) from data; +----------+ | count(*) | +----------+ | 90122 | +----------+ 1 row in set (0.02 sec) kris@localhost [kris]> select count(*) from data; +----------+ | count(*) | +----------+ | 80362 | +----------+ 1 row in set (0.01 sec)The complete example is available on github.com. https://isotopp.github.io/2020/09/24/mysql-deleting-data.html
0 notes
Text
Bouncing Bullet Problem
This is a problem that was presented to me through the google foobar challenge, but my time has since expired and they had decided that I did not complete the problem. I suspect a possible bug on their side, because I passed 9/10 test cases (which are hidden from me) but I'm unsure. I'd really like to know where or if I made a mistake, so I'll ask the problem here.
The problem is as follows: you are standing in a room with integer dimensions, where the left wall exists at $x=0$, and the right wall exists at $x=x_0$. Similarly, the bottom wall exists at $y=0$ and the top wall exists at $y=y_0$. Within this room, you and another individual (which we call a guard) stand on the integer lattice such that your coordinates are at $[x_{s}, y_{s}]$, and the guard stands at $[x_g, y_g]$, where
$$ 0<x_s<x_0 \\ 0<x_g<x_0 \\ 0<y_s<y_0 \\ 0<y_g<y_0 \\ y_s \neq y_g~\text{or}~x_s \neq x_g \\ $$
that is, neither you nor the guard is standing on a wall, and you occupy distinct positions in the room. If you have a bullet which can travel a total distance $d$, then determine the number of distinct directions in which you can fire the bullet such that it hits the other individual, travels a distance less than or equal to $d$, and it does not hit yourself in the process. This is written as a function:
solution(room_dimensions, your_position, guard_position, d)
What I had noticed in my solution was that the allowed directions can be written as a vector of the total distance traveled by the bullet in a specific dimension, where a negative sign indicates initial movement towards $x=0$ or $y=0$, and a positive sign indicates initial movement towards $x=x_0$ or $y=y_0$. Let's give an example of what this means.
Suppose the room has dimensions $[2, 3]$ and you stand at $[1, 2]$ and the guard stands at $[1, 1]$. Then, of course the bullet could go straight down: $[0, -1]$ is a valid bearing. However, we could bounce the bullet off of the left wall, and then have the bullet hit the guard: $[-2, -1]$. That $-2$ is valid because the total distance traveled is $2$: $1$ unit is traveled in moving from your position to the left wall, and an additional $1$ from moving back towards the guard. It is negative because we are moving towards the left wall $x=0$. This can be extended the any number of bounces off of each wall, and each dimension can be considered independently. So, for each dimension, I generate a list of the allowed distances (with sign indicating direction) which results in the bullet arriving at the same coordinate as the guard in that dimension.
If we generate the aforementioned lists (allowed_x, allowed_y) for the $x$ and $y$ dimensions, then $[X, Y]$ $X\in$ allowed_x, $Y\in$ allowed_y is a valid bearing which will take the bullet from you to the guard, with two created problems: 1) The bullet may first pass through you, and 2) Some of these bearings may point in the same direction and travel different distances.
If we determine all of the directions that result in you being hit by the bullet, we can see if a parallel direction exists in the list of directions which result in the guard being hit, and if it does and the path to you being hit is shorter, then that is not a valid direction as it requires the bullet to pass through you. This resolves 1).
2) Is resolved by checking to see if directions are parallel before counting them, and if they are, we record the shorter of the two distances. In this way, we only get distinct directions.
As I said, my code works for 9/10 tests, which are hidden from me. As a result, it is likely that the 1/10 case is specifically chosen to test an extreme which, at random, you would not encounter. I thoroughly tested my code, so I don't believe such an extreme exits, but I would be very relieved if someone could point out my oversight. Cheers!
I've attached my python 2.7.13 code below if anyone wants to get very involved.
from fractions import gcd from random import randint def get_1D_bearings(t, m, g, distance): ''' Returns a list of the total distance travelled in 1D which results in the beam arriving at the guard's t-coordinate. Parameters: t(int): The length of this dimension. m(int): The t-coodinate of the shooter (me). g(int): The t-coordinate of the guard. distance(int): The maximum allowed distance that the beam may travel. ''' i = 0 bearings = [] path = g - m # Direct path from the shooter to the guard with no bounces. if abs(path) <= distance: bearings.append(path) while True: # Initial bounce off of the positive wall and final bounce off of the positive wall. path = (t - m) + (t-g) + 2*i*t if abs(path) <= distance: bearings.append(path) # Initial bounce off of the negative wall and final bounce off of the negative wall. path = - (m+g+2*i*t) if abs(path) <= distance: bearings.append(path) # Initial bounce off of the positive wall and final bounce off of the negative wall. path = (t - m) + g + (2*i+1)*t if abs(path) <= distance: bearings.append(path) # Initial bounce off of the negative wall and final bounce off of the positive wall. path = - ( m + (t - g) + (2*i+1)*t) if abs(path) <= distance: bearings.append(path) else: break i += 1 return bearings def are_parallel(a, b): ''' Returns if the bearings given by a and b are parallel vectors. Parameters: a(array-like): A 2D-array of integers. b(array-like): A 2D-array of integers. ''' x1, y1 = a x2, y2 = b div1 = abs(gcd(x1, y1)) div2 = abs(gcd(x2, y2) ) if div1 == 0 or div2 ==0: if not div1 == 0 and div2 == 0: return False elif (x1 == 0 and x2 == 0) and (y1 // abs(y1) == y2 // abs(y2)): return True elif (y1 == 0 and y2 ==0) and (x1 // abs(x1) == x2 // abs(x2)): return True else: return False else: if x1 // div1 == x2 // div2 and y1 // div1 == y2 // div2: return True else: return False class VectorsNotParallel(Exception): '''Raise this exception when handling vectors which are assumed to be parallel but are not.''' def __init__(self): pass def get_shorter_bearing(a, b): ''' Returns the shorter vector of a and b. If they are not parallel, raises VectorsNotParallel. Parameters: a(array-like): A 2D-array of integers indicating a direction. b(array-like): A 2D-array of integers indicating a direction. ''' if not are_parallel(a, b): raise VectorsNotParallel("These bearings point in different directions: " + str(a) + " and " + str(b)) x1, y1 = a x2, y2 = b if x1 == 0: if abs(y1) < abs(y2): return a else: return b if y1 == 0: if abs(x1) < abs(x2): return a else: return b div1 = abs(gcd(x1, y1)) div2 = abs(gcd(x2, y2) ) if div1 < div2: return a else: return b def get_all_bearings(dimensions, your_position, guard_position, distance): ''' Combines the allowed distances from each of the two dimensions to generate a list of all of the allowed directions that can be shot in which take a beam from your_position to guard_position while not travelling further than the provided distance. Note that some of these directions include passing through your_position. Parameters: dimensions(array-like): A 2D-array of integers indicating the size of the room. your_position(array-like): A 2D-array of integers indicating your position in the room. guard_position(array-like): A 2D-array of integers indicating the guard's position in the room. distance(int): An integer indicating the maximum distance the beam can travel. Returns: bearings(array-like): An array of 2D-arrays indicating the bearings which move the beam from your_position to guard_position. ''' dx, dy= dimensions sx, sy = your_position gx, gy = guard_position allowed_x = get_1D_bearings(dx, sx, gx, distance) allowed_y = get_1D_bearings(dy, sy, gy, distance) bearings = [] for x in allowed_x: for y in allowed_y: if x**2 + y**2 < 1 or x**2 + y**2 > distance **2: continue res = [x, y] append = True # Do we need to append to the list of bearings or just update an existing one for bearing in bearings: if are_parallel(res, bearing): append = False res_2 = get_shorter_bearing(res, bearing) bearing[0] = res_2[0] bearing[1] = res_2[1] if append: bearings.append(res) return bearings def count_friendly_fires(friendly_bearings, guard_bearings): ''' Returns the number of bearings which result in the guard being hit only after the beam passes through the shooter (which is not allowed). Parameters: friendly_bearings(array-like): An array of 2D arrays which indicate bearings that reach the shooter. guard_bearings(array-like): An array of 2D arrays which indicate bearings that reach the guard. ''' count = 0 for f_bearing in friendly_bearings: for g_bearing in guard_bearings: if are_parallel(f_bearing, g_bearing): if get_shorter_bearing(f_bearing, g_bearing) == f_bearing: print(f_bearing, g_bearing) count += 1 return count def solution(dimensions, your_position, guard_position, distance): ''' Returns the number of distinct directions that take a bullet from your_position to guard_position within the allowed distance. Parameters: dimensions(array-like): A 2D-array of integers indicating the size of the room. your_position(array-like): A 2D-array of integers indicating your position in the room. guard_position(array-like): A 2D-array of integers indicating the guard's position in the room. distance(int): An integer indicating the maximum distance the beam can travel. ''' guard_hitting_bearings = get_all_bearings(dimensions, your_position, guard_position, distance) self_hitting_bearings = get_all_bearings(dimensions, your_position, your_position, distance) count = count_friendly_fires(self_hitting_bearings, guard_hitting_bearings) return len(guard_hitting_bearings) - count
from Hot Weekly Questions - Mathematics Stack Exchange from Blogger https://ift.tt/2ZZ15P9
0 notes
Text
Assignment two
Concept: Computer languages brings new possibilities in visual expression
In my study background, I am major in computer science and media arts. I like logical programming and also I am deeply attracted by artistic creation. I am thinking explore both at once with generative art, a sublime combination of computer languages and art. Generative art derived from computer code, is a relatively new format, in which the artist-programmer realises a vision or idea by defining parameters and commands. But making Generative art is, in many ways, just like using different computer languages as "paint brush".
Traditional artistic creation contains many visual expressions, like pencil sketch, oil painting, or gouache paint etc. These are the language of traditional art. There are also many languages in the computer, like python, java or c ++ etc. The different visual expressions come with different computer language.

Google collaborate with London's Barbican Centre project to a new program - DevArt. DevArt is a celebration of art made with code by artists that push the possibilities of creativity - where technology is their canvas and code is their raw material. Google hopes to inspire coders to get the development of code art. The program divided all artwork into four categories, which are Languages (java, python), Toolkits (angularjs, opengl ...), platforms (android, ios, linux ...), and APIs github, tumblr ...).

Language: Python
During my research I discovered Hailei Wang’s artwork “Painting with Code” is a good example to demonstrate computer language - Python as a tool brings new possibilities in visual expression. Wang’s work is divided into three parts “Algorithm as Art”, “Unlimited Complexity” and “Functional Designs”. “Algorithm as Art”, Wang says “computer graphics are based on mathematics”, he created this work, and inspiration came with an algorithm named Cornu Curve, which generates this fantastic visual effect of crazy waves by python.


“Unlimited Complexity”, In this art work, Wang’s goal is to use the complex texture to create the visual effect of catching or entrapping the audience in the “eye”. This artwork composed of millions of shapes can be drawn in just a few minutes, to compare with hand, the same piece might take a human ten years to accomplish. So we can see how powerful of the computer languages to create the art. And it brings a unique effect.



“Functional Designs”, Wang wants demonstrate code painting it is not only beautiful, but also usable. He points he can create new patterns and unique fabrics for the fashion industry, or he can move beyond two-dimensional creations and use generative art to make sculpture, furniture, and even architecture.


Language: Java
In my research, I found Amir Sarid’s artwork The Musician’s Dream, is good example to demonstrate computer language java with openGL to brings new possibilities in visual expression. The description of his artwork is he transfers music into a 3-d video scene. He seeks to implant musical data into a three-dimensional simulation of a natural scene. Java with OpenGL is a great tool to create 3D shape.



Experiment on Python & Java
Python
This is my experiment on using Python with Turtle graphics.







Experiment On using Java with OpenGL





After all experiment i did. I found python turtle graphics is a great tool to create 2d graphics, code is easy, logical is clear, and really sample to create. The disadvantage is can’t create 3d shape. Java OpenGL is a great tool to create 3d graphics. The disadvantage is code is more complicated than python graphics. It is possible to see from the results of the experiment that different languages will produce different visual expression.
My artwork:
After these research and experience, I made my own artwork. The Description of my artwork: A black hole is a place where gravity pulls so much that even light cannot get out. Black hole is invisible, because no light can get out. Light come with seven colors: red, orange, yellow, green, blue, indigo and violet.
Image that your eye is a spectrometer, in which seven colors of light surround the black hole.

In my artwork, I am using computer language: python, Create the animation of black hole formation. Thousands of different colored lines refer to light. The trajectory of motion is that light is formed in space by gravity.
Tech Description:
Computer languages: Python 2.7.5

Toolkits: python Turtle graphics.
Platforms: Mac based on Linux.
API: Github, tumblr
Code Example:

from turtle import * #import python turtle graphics
speed(0) #speed of the motion, 0 refers to fastest
bgcolor(’black’) # background colour, refers to Space
x = 1 # set initial variable x
while x < 4000: # using while loop to create ‘light’, if >=4000 jump out while loop
red = randint(0,255) #set colour
fd(500+x) # ‘light’ length
rt(260) # the angle of rotation refers to light tracing
x+=1 # helps jump out the while loop
Artwork(video):

youtube
Conclusion:
Creating art with computer languages. Computers have revolutionised countless aspects of human life, and now, computer languages have the potential to revolutionise artistic expression, opening infinite space for innovation.
0 notes